Introduzione
PostgreSQL è uno dei sistemi di gestione di database relazionali più avanzati e diffusi al mondo, apprezzato per la sua affidabilità, robustezza e aderenza agli standard SQL. Tuttavia, anche un DBMS così sofisticato può trovarsi in difficoltà quando lo spazio su disco si esaurisce, causando interruzioni del servizio e potenziali perdite di dati. Questo problema, apparentemente banale, può avere cause complesse e richiedere un’analisi approfondita per essere risolto efficacemente.
In questo articolo esploreremo le metodologie per individuare le cause dell’esaurimento dello spazio disco in PostgreSQL, analizzeremo i vari fattori che possono contribuire a questo problema, e offriremo soluzioni pratiche per risolverlo e prevenirne il verificarsi in futuro.
Sintomi di un disco in esaurimento
Prima di parlare di diagnostica, vediamo quali sono i sintomi (o le evidenze) che indicano un imminente o già avvenuto esaurimento dello spazio disco:
- Errori nei log di PostgreSQL che indicano “No space left on device” (beh, questa era facile…)
- Query che improvvisamente falliscono, specialmente quelle che comportano operazioni di scrittura
- Impossibilità di creare nuovi file del WAL (Write-Ahead Logging)
- Rallentamenti significativi nelle prestazioni del database
- Impossibilità di eseguire backup o dump del database
- Messaggi di errore durante le operazioni VACUUM o ANALYZE
Strumenti diagnostici essenziali
1. Verifica dello spazio disponibile sul filesystem
Il primo passo consiste nel verificare lo spazio effettivamente disponibile sui dischi. Il comando df è lo strumento fondamentale per questa analisi:
df -h

Questo comando mostra l’utilizzo dello spazio disco per tutti i filesystem montati. La colonna “Use%” indica la percentuale di spazio utilizzato. Valori superiori al 90% sono generalmente considerati critici.
Per un’analisi più dettagliata, è possibile utilizzare:
df -i
Questo comando mostra l’utilizzo degli inode. In alcuni casi, si potrebbe avere spazio disponibile ma esaurire gli inode (specialmente in presenza di molti file di piccole dimensioni).
2. Analisi dell’occupazione dello spazio della directory PostgreSQL
Per identificare quali directory e file occupano più spazio all’interno della directory di dati di PostgreSQL:
du -h --max-depth=1 /var/lib/postgresql/dataQuesto comando visualizza l’occupazione di spazio per le sottodirectory immediate. È possibile ripetere il comando nelle directory che occupano più spazio per un’analisi più granulare.
3. Analisi dello spazio utilizzato dai database
Dall’interno di PostgreSQL, è possibile analizzare lo spazio occupato dai database:
SELECT pg_database.datname, pg_size_pretty(pg_database_size(pg_database.datname)) AS sizeFROM pg_databaseORDER BY pg_database_size(pg_database.datname) DESC;
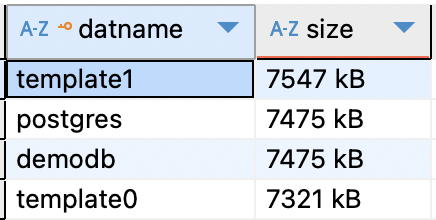
Questa query mostra le dimensioni di ogni database ordinati dal più grande al più piccolo.
4. Identificazione delle tabelle più grandi
Una volta identificato il database che occupa più spazio, è possibile analizzare le dimensioni delle singole tabelle:
SELECT
nspname || '.' || relname AS "relation",
pg_size_pretty(pg_total_relation_size(C.oid)) AS "total_size",
pg_size_pretty(pg_relation_size(C.oid)) AS "data_size",
pg_size_pretty(pg_total_relation_size(C.oid) - pg_relation_size(C.oid)) AS "external_size"
FROM
pg_class C
LEFT JOIN pg_namespace N ON (N.oid = C.relnamespace)
WHERE
nspname NOT IN ('pg_catalog', 'information_schema')
AND C.relkind <> 'i'
AND nspname !~ '^pg_toast'
ORDER BY
pg_total_relation_size(C.oid) DESC
LIMIT 20;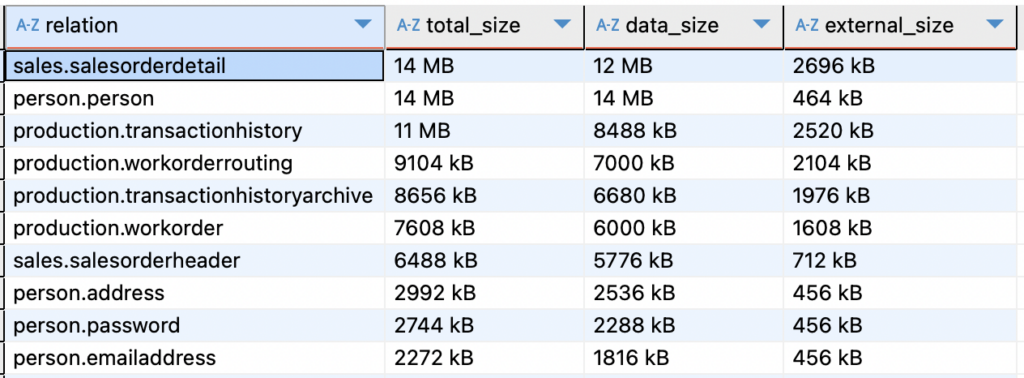
Questa query mostra le 20 tabelle più grandi, indicando la dimensione totale, la dimensione dei dati e quella degli elementi esterni (indici, TOAST, ecc.).
5. Analisi degli indici
Gli indici possono occupare una quantità significativa di spazio:
SELECT
idx.relname AS index_name,
pg_size_pretty(pg_relation_size(idx.oid)) AS index_size,
tab.relname AS table_name
FROM
pg_index i
JOIN pg_class idx ON idx.oid = i.indexrelid
JOIN pg_class tab ON tab.oid = i.indrelid
ORDER BY
pg_relation_size(idx.oid) DESC
LIMIT 20;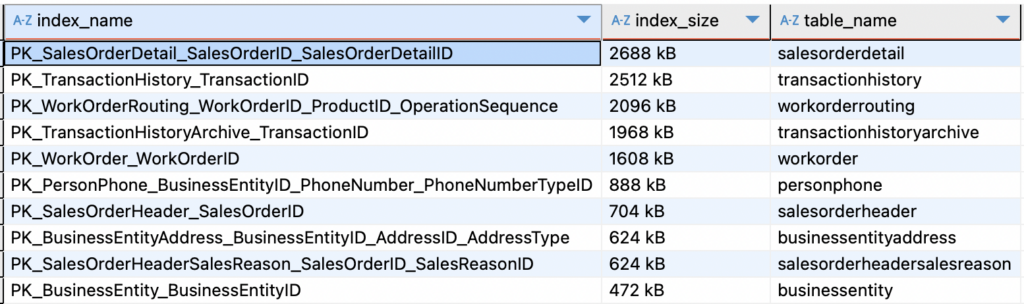
Cause comuni di esaurimento dello spazio disco
1. File WAL accumulati
I file WAL (Write-Ahead Logging) sono essenziali per garantire l’integrità dei dati, ma possono accumularsi rapidamente:
Diagnosi:
ls -lah /var/lib/postgresql/data/pg_wal/Questo comando mostra i file WAL presenti nella directory. Un numero elevato di file può indicare un problema.
Possibili problemi:
- Configurazione di archive_command non funzionante: Se
archive_commandè configurato ma fallisce silenziosamente, i file WAL non vengono eliminati. - Replica in stallo: Se è configurata la replica ma i server di standby sono disconnessi o in ritardo, i file WAL vengono conservati.
- Elevato tasso di transazioni: Database con un alto volume di transazioni generano molti file WAL.
Verifica della configurazione:
SHOW wal_keep_segments;
SHOW archive_mode;
SHOW archive_command;2. Tabelle in crescita eccessiva
Le tabelle possono crescere eccessivamente per varie ragioni:
Diagnosi:
SELECT
schemaname,
relname,
n_live_tup,
n_dead_tup,
last_vacuum,
last_autovacuum
FROM
pg_stat_user_tables
ORDER BY
n_dead_tup DESC;Questa query mostra le tabelle con il maggior numero di tuple morte, che possono causare “bloat”.
Possibili problemi:
- VACUUM inefficace: Se VACUUM non viene eseguito regolarmente o fallisce, le tuple morte non vengono recuperate.
- Autovacuum non ottimizzato: Le impostazioni predefinite di autovacuum potrebbero non essere adeguate per tabelle molto grandi o con un alto tasso di aggiornamenti.
- Inattività delle operazioni di pulizia: L’assenza di date nelle colonne
last_vacuumelast_autovacuumindica che la tabella non viene pulita.
3. File temporanei
PostgreSQL crea file temporanei per alcune operazioni come ordinamenti, hash join, o risultati di query temporanee:
Diagnosi:
du -h --max-depth=1 /var/lib/postgresql/data/base/pgsql_tmp/Possibili problemi:
- Query complesse senza indici adeguati: Query che richiedono ordinamenti o join su grandi set di dati senza indici appropriati.
- Valore work_mem troppo basso: Un valore basso di
work_memporta PostgreSQL a utilizzare file temporanei più frequentemente. - Operazioni di massa senza controllo: Operazioni come COPY o bulk inserts possono generare molti file temporanei.
Verifica delle impostazioni:
SHOW work_mem;
SHOW temp_file_limit;4. File di backup
I file di backup possono occupare molto spazio se non gestiti correttamente:
Diagnosi:
find /var/lib/postgresql/data -name "*.bak" -o -name "*.backup" -o -name "*.sql" | xargs du -chPossibili problemi:
- Backup vecchi non eliminati: Script di backup che non rimuovono le versioni precedenti.
- Dump SQL nella directory del database: Esportazioni SQL lasciate nella directory dei dati.
- File di base backup per PITR: File di base backup per Point-In-Time Recovery che non vengono gestiti correttamente.
5. File di log sovradimensionati
I log di PostgreSQL possono crescere notevolmente, specialmente con configurazioni di logging verbose:
Diagnosi:
ls -lah /var/log/postgresql/Possibili problemi:
- Rotazione dei log non configurata: Mancanza di una configurazione per la rotazione automatica dei log.
- Livello di logging troppo dettagliato: Impostazioni come
log_statement = 'all'generano molti log. - Log_line_prefix complesso: Un prefisso di log molto dettagliato aumenta la dimensione di ogni riga.
Verifica delle impostazioni:
SHOW log_directory;
SHOW logging_collector;
SHOW log_filename;
SHOW log_rotation_age;
SHOW log_rotation_size;
6. Bloat delle tabelle e degli indici
Il “bloat” si verifica quando tabelle e indici contengono spazio allocato ma inutilizzato:
Diagnosi del bloat delle tabelle:
SELECT
current_database(), schemaname, tablename,
ROUND(CASE WHEN otta=0 THEN 0.0 ELSE sml.relpages/otta::numeric END,1) AS tbloat,
CASE WHEN relpages < otta THEN 0 ELSE relpages::bigint - otta END AS wastedpages,
CASE WHEN relpages < otta THEN 0 ELSE (bs*(relpages-otta))::bigint END AS wastedbytes
FROM (
SELECT
schemaname, tablename, cc.reltuples, cc.relpages, bs,
(CEIL((cc.reltuples*((datahdr+ma-
(CASE WHEN datahdr%ma=0 THEN ma ELSE datahdr%ma END))+nullhdr2+4))/(bs-20::float))
) AS otta
FROM (
SELECT
ma,bs,schemaname,tablename,
(datawidth+(hdr+ma-(case when hdr%ma=0 THEN ma ELSE hdr%ma END)))::numeric AS datahdr,
(maxfracsum*(nullhdr+ma-(case when nullhdr%ma=0 THEN ma ELSE nullhdr%ma END)))::numeric AS nullhdr2
FROM (
SELECT
schemaname, tablename, hdr, ma, bs,
SUM((1-null_frac)*avg_width) AS datawidth,
MAX(null_frac) AS maxfracsum,
hdr+(
SELECT 1+count(*)/8
FROM pg_stats s2
WHERE null_frac<>0 AND s2.schemaname = s.schemaname AND s2.tablename = s.tablename
) AS nullhdr
FROM pg_stats s, (
SELECT
(SELECT current_setting('block_size')::numeric) AS bs,
CASE WHEN SUBSTRING(SPLIT_PART(v, ' ', 2) FROM '#"[0-9]+.[0-9]+#"%' for '#')
IS NULL THEN 8 ELSE 4 END AS hdr,
CASE WHEN v ~ 'mingw32' OR v ~ '64-bit' THEN 8 ELSE 4 END AS ma
FROM (SELECT version() AS v) AS foo
) AS constants
GROUP BY 1,2,3,4,5
) AS foo
) AS rs
JOIN pg_class cc ON cc.relname = rs.tablename
JOIN pg_namespace nn ON cc.relnamespace = nn.oid AND nn.nspname = rs.schemaname AND nn.nspname <> 'information_schema'
) AS sml
WHERE schemaname NOT IN ('pg_catalog', 'information_schema')
ORDER BY wastedbytes DESC;Diagnosi del bloat degli indici:
SELECT
current_database(), nspname AS schemaname, tblname, idxname,
ROUND(CASE WHEN otta=0 THEN 0.0 ELSE sml.relpages/otta::numeric END,1) AS ibloat,
CASE WHEN relpages < otta THEN 0 ELSE relpages::bigint - otta END AS wastedpages,
CASE WHEN relpages < otta THEN 0 ELSE (bs*(relpages-otta))::bigint END AS wastedbytes
FROM (
SELECT
nspname, tblname, idxname, bs, relpages,
CEIL((reltuples*(6+ma-
(CASE WHEN ma=8 THEN 1 ELSE 0 END))+16)/(bs-20::float)) AS otta
FROM (
SELECT
n.nspname, i.tblname, i.idxname, i.reltuples, i.relpages,
(SELECT 8 WHERE false) AS ma,
(SELECT current_setting('block_size')::numeric) AS bs
FROM (
SELECT
ic.relname AS idxname,
ic.reltuples,
ic.relpages,
(SELECT tc.relname FROM pg_class tc WHERE tc.oid = ic.relam) AS tablename,
n.nspname,
(SELECT relname FROM pg_class WHERE oid = indrelid) AS tblname
FROM
pg_class ic
JOIN pg_namespace n ON n.oid = ic.relnamespace
JOIN pg_index i ON i.indexrelid = ic.oid
WHERE
ic.relkind = 'i'
) i
) AS foo
) AS sml
WHERE sml.relpages - otta > 0
ORDER BY wastedbytes DESC;7. Database di sistema sovradimensionati
I database di sistema come template1, template0 e postgres possono crescere inaspettatamente:
Diagnosi:
SELECT datname, pg_size_pretty(pg_database_size(datname)) FROM pg_database WHERE datname IN ('template0', 'template1', 'postgres');Soluzioni pratiche
1. Gestione dei file WAL
- Verificare e correggere
archive_command:archive_command = 'test ! -f /mnt/server/archivedir/%f && cp %p /mnt/server/archivedir/%f'
Assicurarsi che il comando restituisca 0 solo in caso di successo. - Impostare
wal_keep_segmentsappropriatamente:ALTER SYSTEM SET wal_keep_segments = 10; -- Valore predefinito: 0 - Attivare il recycling dei WAL se non è necessaria l’archiviazione:
ALTER SYSTEM SET archive_mode = off; - Ridurre la dimensione dei segmenti WAL (richiede riavvio):
ALTER SYSTEM SET wal_segment_size = '16MB'; -- Il valore predefinito è 16MB
2. Ottimizzazione di VACUUM e gestione del bloat
- Configurazione di autovacuum per tabelle grandi:
ALTER TABLE nome_tabella SET (autovacuum_vacuum_scale_factor = 0.01, autovacuum_analyze_scale_factor = 0.005); - Esecuzione manuale di VACUUM FULL per recuperare spazio:
VACUUM FULL VERBOSE nome_tabella;
Nota: VACUUM FULL blocca la tabella e crea una copia completa. Utilizzare con cautela su tabelle di produzione. Valutare pg_repack (vedi più avanti) - Ricostruzione degli indici per ridurre il bloat:
REINDEX TABLE nome_tabella;
o per un indice specifico:REINDEX INDEX nome_indice; - Utilizzo di pg_repack per operazioni non bloccanti:
pg_repack -d nome_database -t nome_tabella
pg_repack è un’estensione che permette di riorganizzare tabelle con minimo impatto sulle operazioni.
3. Gestione dei file temporanei
- Aumentare work_mem per ridurre l’uso di file temporanei:
ALTER SYSTEM SET work_mem = '16MB'; -- Il valore predefinito è 4MB - Impostare un limite per i file temporanei:
ALTER SYSTEM SET temp_file_limit = '1GB'; - Spostare la directory dei file temporanei su un filesystem diverso:
ALTER SYSTEM SET temp_tablespaces = 'temp_tablespace';
4. Gestione dei log
- Configurare la rotazione dei log:
ALTER SYSTEM SET log_rotation_age = '1d'; ALTER SYSTEM SET log_rotation_size = '100MB'; - Ridurre il livello di dettaglio del logging:
ALTER SYSTEM SET log_statement = 'none'; -- oppure 'ddl', 'mod', 'all' - Configurare la compressione dei log:
ALTER SYSTEM SET log_filename = 'postgresql-%Y-%m-%d_%H%M%S.log';
Quindi configurare logrotate per comprimere i file rotati.
5. Partitioning delle tabelle grandi
Per tabelle che crescono continuamente, il partitioning può essere una soluzione efficace:
CREATE TABLE misurazioni (
id serial,
time_stamp timestamp,
valore float
) PARTITION BY RANGE (time_stamp);
CREATE TABLE misurazioni_y2025m01 PARTITION OF misurazioni
FOR VALUES FROM ('2025-01-01') TO ('2025-02-01');
CREATE TABLE misurazioni_y2025m02 PARTITION OF misurazioni
FOR VALUES FROM ('2025-02-01') TO ('2025-03-01');Questo permette di archiviare o eliminare facilmente i dati vecchi senza impatto sulle prestazioni.
6. Implementazione di politiche di retention dei dati
- Eliminazione periodica dei dati vecchi:
DELETE FROM logs WHERE log_date < current_date - interval '90 days'; - Archiviazione dei dati storici:
CREATE TABLE logs_archive ASSELECT * FROM logs WHERE log_date < current_date - interval '90 days';DELETE FROM logs WHERE log_date < current_date - interval '90 days';
7. Monitoraggio proattivo dello spazio disco
- Integrazione con sistemi di monitoraggio come Prometheus/Grafana, Zabbix, o Nagios per avvisi preventivi.
Prevenzione a lungo termine
1. Dimensionamento adeguato dell’infrastruttura
- Calcolare il tasso di crescita medio del database e pianificare l’espansione dello storage di conseguenza.
- Considerare l’implementazione di storage elastico per database ospitati in cloud.
- Separare i file WAL, i dati e i file temporanei su dispositivi di storage diversi.
2. Automatizzazione della manutenzione
- Schedulare job regolari per VACUUM, ANALYZE e monitoraggio dello spazio.
- Implementare script per la pulizia automatica dei backup vecchi e dei log.
- Creare procedure per l’archiviazione e la purga dei dati storici.
3. Ottimizzazione della configurazione
La configurazione ottimale di PostgreSQL dipende molto dall’hardware disponibile e dal carico di lavoro. Alcuni parametri chiave da considerare:
maintenance_work_mem: Influenza l’efficienza di VACUUM.autovacuum_vacuum_thresholdeautovacuum_vacuum_scale_factor: Controllano quando autovacuum si attiva.autovacuum_naptime: Controlla la frequenza con cui autovacuum si esegue.checkpoint_timeoutemax_wal_size: Influenzano la gestione dei WAL.
4. Architettura dei dati consapevole
- Utilizzare tipi di dati appropriati per minimizzare lo spazio utilizzato (es. smallint invece di integer quando possibile).
- Implementare strategie di compressione per colonne con dati ripetitivi.
- Considerare l’utilizzo di estensioni come TimescaleDB per dati time-series.
- Valutare l’implementazione di soluzioni di archiviazione a freddo per dati storici raramente acceduti.
Conclusione
L’esaurimento dello spazio disco in PostgreSQL è un problema che può avere molteplici cause e richiede un approccio metodico per essere diagnosticato e risolto efficacemente. Comprendere l’architettura di storage di PostgreSQL, le dinamiche di crescita dei dati e implementare strategie proattive di monitoraggio e manutenzione sono elementi chiave per prevenire interruzioni del servizio dovute a problemi di spazio.
Con gli strumenti e le strategie presentati in questo articolo, gli amministratori di database dovrebbero essere in grado di identificare rapidamente le cause di un disco esaurito, implementare soluzioni immediate per ripristinare il servizio e sviluppare piani a lungo termine per prevenire il ripetersi del problema.
Ricordate che ogni ambiente PostgreSQL è unico, con carichi di lavoro e modelli di utilizzo specifici. Le strategie di gestione dello spazio disco dovrebbero essere personalizzate per adattarsi alle caratteristiche specifiche della vostra installazione e ai requisiti dei vostri utenti.